技術文章
技術問答
iT 徵才
聊天室
2026 鐵人賽
登入/註冊
文章
問答
Tag
邦友
鐵人賽
搜尋
第 12 屆 iThome 鐵人賽
DAY
15
0
AI & Data
AWS 數據處理與分析實戰
系列 第
15
篇
Day 15 Glue ETL Job 教學 - Part 2
12th鐵人賽
eric88348
2020-09-29 13:34:37
1952 瀏覽
分享至
完成 S3 資料源的準備後,我們來看如何使用 Glue ETL Job,先來介紹 Spark 的部分
首先創建一個 Glue Job
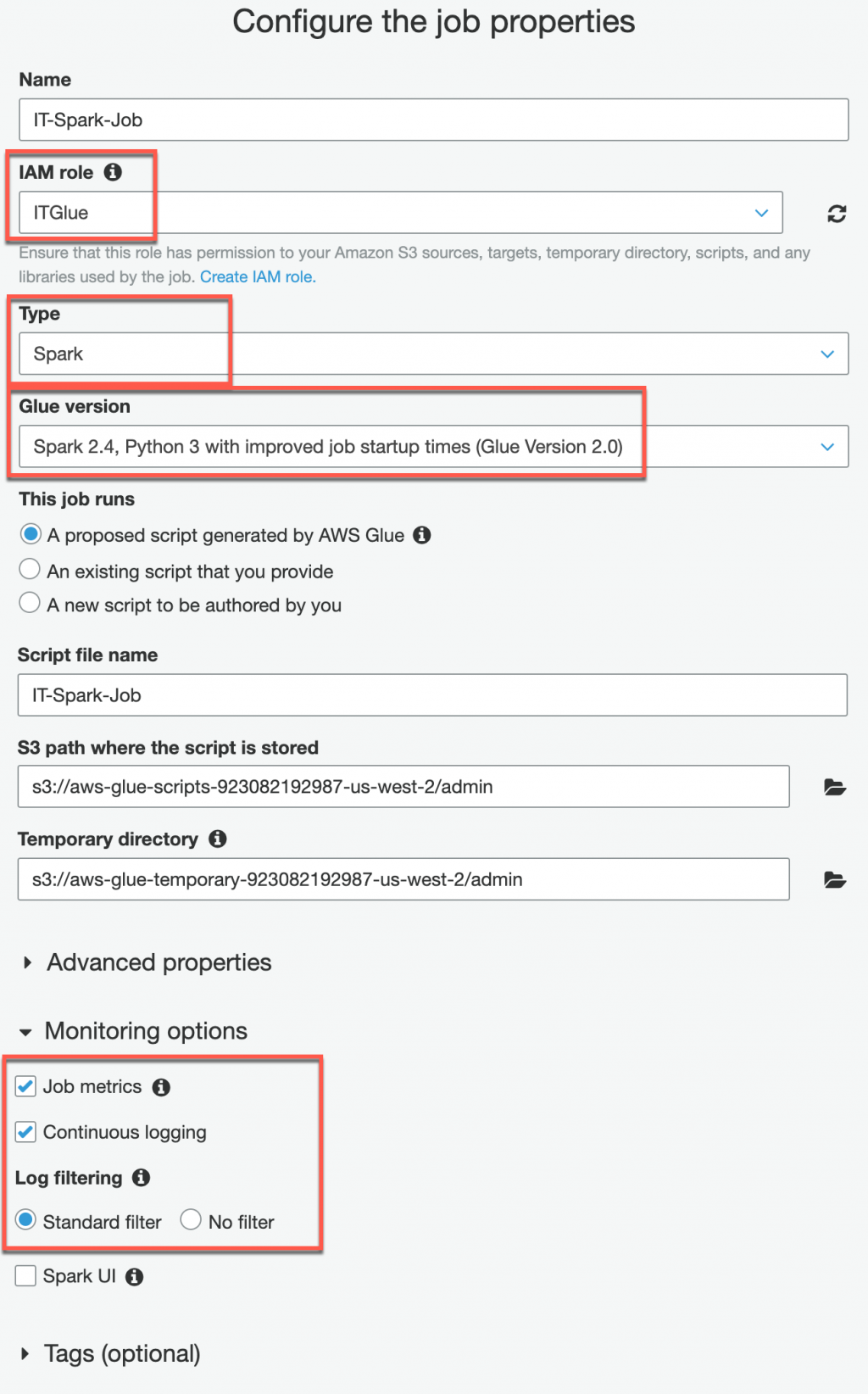
第一個設定頁面是 Job 的基本設定,跟運算有關的都在這邊進行設定
IAM role:這邊的 Role 使用 Day 6 所創建的 Role(ITGlue)
Type:Type 的部分先選擇 Spark
Glue version:選擇最新的 Spark 2.4, Python 3(Glue version 2.0)
Monitoring options:這邊建議 Job metrics 與 Continuous logging 都打勾啟用,可以讓我們在遇到運算失敗時有資訊可以 Troubleshooting
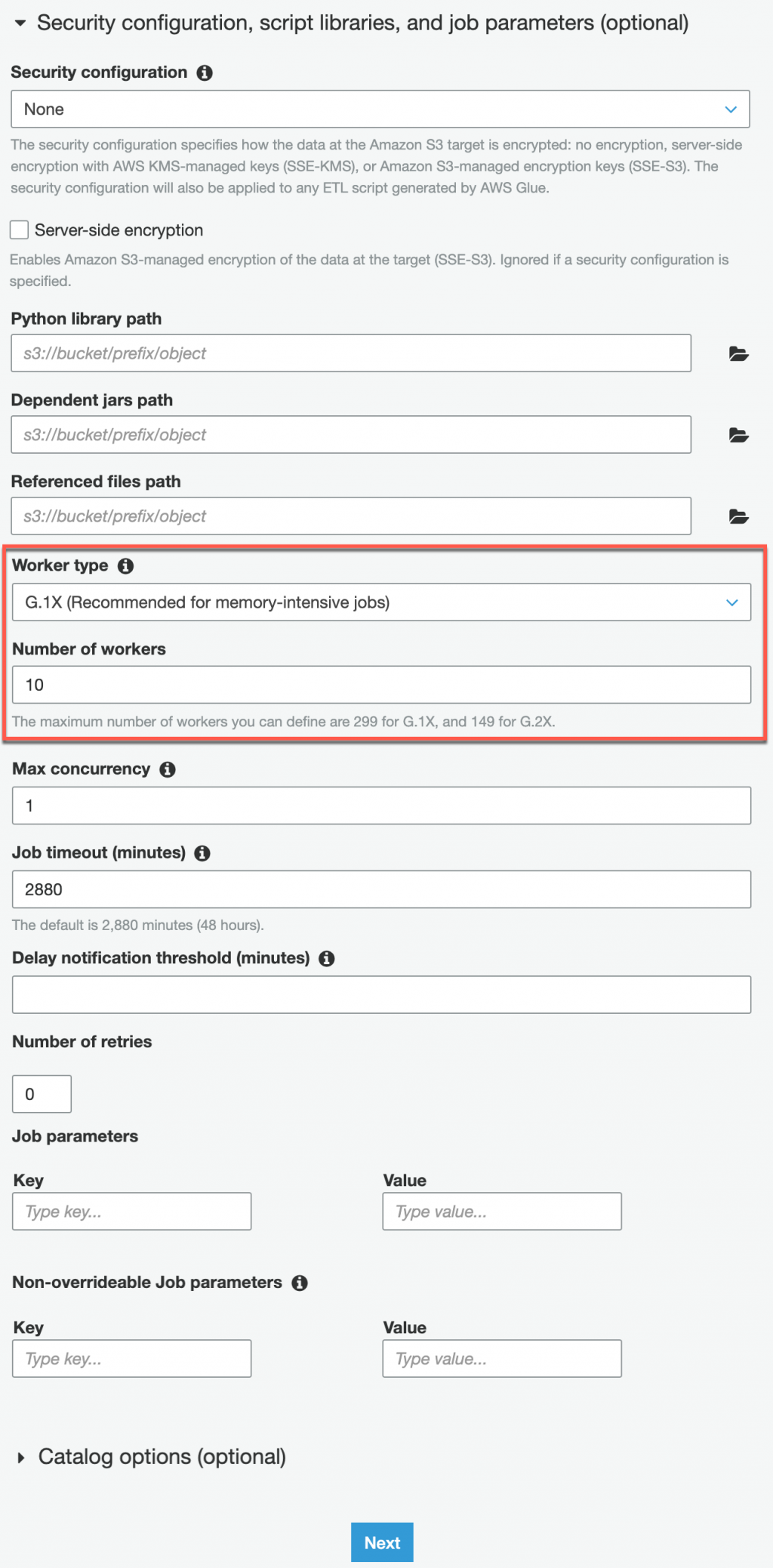
再當前頁面繼續往下可以看到 Security configuration, script libraries, and job parameters (optional) 的選單,這邊可以設定是否加密、Import 而外所需的 Python library,以及設定要使用的運算資源大小
Worker Type:此參數可以設定要使用的運算類型
Standard:此執行類型可以應付單純的資料轉移、資料過濾、欄位拆分或合併
G.1X:如果需要進行 Join、Group、對資料進行計算時,選擇此類型會比較適合,因為在執行這些運算時會使用較多的記憶體
G.2X:進行更複雜的 ETL 計算工作時可能會需要更多的記憶體,這時就可以選擇此類型的運算資源
Number of workers:可以把這個參數想成有多少台 VM 進行運算,每個VM 會根據所選擇的 Worker Type 會有不同的 CPU、Memory
Standard 的 VM 有 4 Core 16G Memory,但每台 VM 會執行兩個 Task
G.1X 的 VM 有 4 Core 16G RAM,每台 VM 只會執行一個 Task,所以 Task 可以有完整的 16G Memory 可以用
G.2X 的 VM 有 8 Core 32G RAM,每台 VM 只會執行一個 Task
其他設定可以維持在默認的狀態下即可
留言
追蹤
檢舉
上一篇
Day 14 Glue ETL Job 教學 - Part 1
下一篇
Day 16 Glue ETL Job 教學 - Part 3
系列文
AWS 數據處理與分析實戰
共
30
篇
目錄
RSS系列文
訂閱系列文
14
人訂閱
26
Day 26 持續同步 S3 資料到 Redshift - Part 1
27
Day 27 持續同步 S3 資料到 Redshift - Part 2
28
Day 28 QuickSight 連接 Redshift - Part 1
29
Day 29 QuickSight 連接 Redshift - Part 2
30
Day 30 QuickSight 功能介紹
完整目錄
熱門推薦
{{ item.subject }}
{{ item.channelVendor }}
|
{{ item.webinarstarted }}
|
{{ formatDate(item.duration) }}
直播中
立即報名
尚未有邦友留言
立即登入留言
iThome鐵人賽
參賽組數
902
組
團體組數
37
組
累計文章數
19838
篇
完賽人數
528
人
看影片追技術
看更多
{{ item.subject }}
{{ item.channelVendor }}
|
{{ formatDate(item.duration) }}
直播中
熱門tag
15th鐵人賽
16th鐵人賽
13th鐵人賽
14th鐵人賽
17th鐵人賽
12th鐵人賽
11th鐵人賽
鐵人賽
2019鐵人賽
javascript
2018鐵人賽
python
2017鐵人賽
windows
php
c#
linux
windows server
css
react
熱門問題
VM主機卡在Initializing storage stack
關於ASUS RS100-E11-PI2的磁碟陣列
趣味SQL,給了一組編號後,用SQL產生亂數編碼的結果
熱門回答
VM主機卡在Initializing storage stack
關於ASUS RS100-E11-PI2的磁碟陣列
趣味SQL,給了一組編號後,用SQL產生亂數編碼的結果
熱門文章
Mac 也能「分身術」!同時開啟多個 Claude Code 與 Claude Desktop 完整教學
公司導入 coding agent,真正該量的不是使用率
從注入攻擊到詐騙防護:@martin_yeung/llm-up-guardrail 為你的 AI 打造生產級安全防線
【Python】1.給 Python 新手的 3 個無痛心法
README 已經不是文件了,它是 coding agent 會執行的社交工程
IT邦幫忙
×
標記使用者
輸入對方的帳號或暱稱
Loading
找不到結果。
標記
{{ result.label }}
{{ result.account }}


 iThome鐵人賽
iThome鐵人賽